


現役の出前館配達員164人にアンケートを取ったところ、なんと49人も「時給換算3,000円超え」を実現※していました。さらに、「時給換算2,000円越え」は122人が実現しています。
10人中7人以上が時給換算2,000円越えを実現※しているのです。(※集計期間:2021年5月11日~2021年9月1日・当方公式LINEにて50回以上配達経験者にアンケートを実施)
他のデリバリーサービスでも、ここまで高い報酬水準を実現するのは難しいのが現状です。
なので、今から始めるのがかつてなく、「一番おいしい」タイミングです。
...ですが、現在出前館配達員の新規登録が非常に人気で登録が殺到しているため、 いつ「登録一時停止」・「新規登録再開の見込みなし」なんていう状況になってもおかしくありません。
しかも、これからもっと配達員が増えてくると、稼ぎにくくなるかもしれません。
下記ボタンが表示されている間は、まだ無料で登録可能なので、少しでも興味がある方は無料登録できる今の内に、登録だけしておくのがいいでしょう。
登録してから、実際に始めるのが1ヶ月後とかも大丈夫ですよ。今の所、まだ登録料は一切かかりません。完全無料で登録ができます。
↑↑(時給換算3,000円超えのチャンスは今の内です...)

最近は「出前館」や「Wolt(ウォルト)」など、様々な配達員で溢れていますが、注文数の多さなどから、やはりUber Eats(ウーバーイーツ)はよく稼げます。
配達を工夫することで、時給2,000円、月収40万円以上も狙えます。

最近は配達員の掛け持ちが主流になりつつありますが、まだ配達員をやったことがないという方は、まずはUber Eats 配達パートナーがおすすめ!
まずは、Uber Eats で配達員のノウハウを掴み、続いて出前館や他の配達員も掛け持ちでやってみる、という流れがオススメです!

今のうちに配達員に登録し、配達に慣れておきましょう!
Uber Eats(ウーバーイーツ)配達パートナーの人気記事はこちら
 ウーバーイーツの給料・時給を公開!稼げるコツも徹底解説!
ウーバーイーツの給料・時給を公開!稼げるコツも徹底解説!
この記事は、以下に当てはまる方におすすめです。
- Uber Eats(ウーバーイーツ)配達パートナーに興味がある方
- Uber Eats(ウーバーイーツ)配達パートナーをこれからやろうと考えている方
- Uber Eats(ウーバーイーツ)配達パートナーのリアルな給料事情を知りたい方
- Uber Eats(ウーバーイーツ)配達パートナーで収入・時給換算が伸び悩んでいる方
結論から言うと、Uber Eats(ウーバーイーツ)配達パートナーの給料・収入は、時給換算で平均1,664円※となります。(※Twitter上で公開されている配達員の売上を参考に算出。)
配達員の中には、時給換算で2,000円超えの方もいらっしゃいますが、そこまでの時給にするにはいくつかのポイントを抑える必要があります。
この記事では、
- Uber Eats(ウーバーイーツ)配達パートナーの収入・時給換算
- Uber Eats(ウーバーイーツ)配達パートナーの収入・時給を上げるコツ
- Uber Eats(ウーバーイーツ)配達パートナーのメリット・デメリット
- Uber Eats(ウーバーイーツ)配達パートナーの報酬(収入)の仕組み
を中心に解説していきます。
これから配達員をされる方、収入・時給が上がらず悩んでいる方の助けになれば幸いです。
それでは、参りましょう!
(今回の記事では、分かりやすく説明するために、「給料 / 収入・時給」といった言葉を使っていますが、本来Uber Eats(ウーバーイーツ)配達パートナーは業務委託制のため、正確には「報酬」という言葉が当てはまります。)
Uber Eats(ウーバーイーツ)配達パートナーの収入・給料は時給換算すると平均1,664円

ここで紹介する金額は、すべてTwitter上で公開されている、実際のUber Eats(ウーバーイーツ)配達パートナーの売上・収入を参考に算出しました。
今回参考にさせていただいた給料・収入データは、この記事の最後にまとめてあります。
Uber Eats(ウーバーイーツ)配達パートナーは一般的なアルバイトよりも稼げる
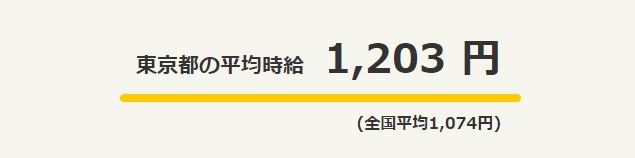
(引用:https://townwork.net/tokyo/jikyuu/)
2021年8月4日時点での、東京都の平均時給は「1,203円」となっています。年々少しずつ上昇しています。
一方、Uber Eats(ウーバーイーツ)配達パートナーの時給平均は「1,664円」ですので、その差額は「461円」。全国平均と比較すると「590円」の差です。
仮に、『東京都、週5日、1日8時間、合計23日間』勤務した場合の給料で比較してみると、
| 平均日給 | 平均月給 | |
| Uber Eats(ウーバーイーツ)配達パートナー | 13,312円 | 306,176円 |
| その他の仕事 | 9,624円 | 221,352円 |
つまり、1週間で「18,440円」、1ヶ月で「84,824円」※ Uber Eats(ウーバーイーツ)配達パートナーの方が多く給料をもらうことができる計算になります。(※金額はあくまで見込みです。配達するエリアや時間帯により金額は変動します。)
Uber Eats(ウーバーイーツ)配達パートナーの各業界の平均時給との比較
各業界ごとの比較は以下の通りです。
| 平均時給(東京都) | Uber Eats(ウーバーイーツ)の時給との差額 | |
| Uber Eats(ウーバーイーツ) | 1,664円 | – |
| 宅配・デリバリー | 1,164円 | 500円 |
| サービス業(店長・マネージャー) | 1,165円 | 499円 |
| イベント・コンサートスタッフ | 1,312円 | 352円 |
| 一般事務 | 1,264円 | 400円 |
| システムエンジニア | 1,296円 | 368円 |
| 看護師・准看護師 | 1,863円 | -199円 |
| 薬剤師 | 2,036円 | -372円 |
さすがに、国家資格が必要な看護師や薬剤師の時給・給料には劣りますが、他業界と比較しても、かなり高額であることがわかります。
コンビニエンスストアやスーパーなどのサービス業の店長よりも500円ほど高く、また専門知識や技術、資格などが必要とされる職業とほぼ同じ水準の時給であるということは、Uber Eats(ウーバーイーツ)配達パートナーをやる上での大きな魅力です。
しかも、Uber Eats(ウーバーイーツ)配達パートナーは、特別な資格や技術は必要なく、だれでも気軽に始められる上に、時給・給料が高い!という点も、かなり嬉しいですね。

Uber Eats(ウーバーイーツ)配達パートナーには、誰でも稼げるポテンシャルがあります!
>>Uber Eats(ウーバーイーツ)配達パートナー公式登録ページ
Uber Eats(ウーバーイーツ)配達パートナーで時給2,000円は可能か?
結論から言うと、Uber Eats(ウーバーイーツ)配達パートナーで時給2,000円を超えることは可能です。
ただし、常に時給2,000円を超える、というのは難しいでしょう。
具体的には、
-
- ピーク時間(11:30~13:30 / 19:00~20:30)
- 雨の日
上記タイミングで配達をすれば、時給換算で2,000円を超えて稼ぐことが可能でしょう。注文が集中する時間帯や日を逃さず稼働することで、安定して注文を受け続けることができます。
また、配達を行う際の”いくつかのコツ”を抑えることで、収入・給料UP、平均時給1,600~1,700円程度を稼ぐことが可能です。詳しくは、後ほど解説します。
安定して稼ぎたいなら「出前館」の配達員がおすすめ

Uber Eats(ウーバーイーツ)配達パートナーで多くの給料をもらうには、配達エリアの状況や配達距離の計算など、様々な要素を常に考えて配達する必要があります。
また、配達距離に応じて配達単価も変化するので、安定した収入を得るのは中々大変…と感じるかもしれません。
「もう少し安定して稼げる配達員はないのか?」
という方におすすめしたいのが、フードデリバリーサービス国内大手、「出前館」(業務委託)の配達員です。
Uber Eats(ウーバーイーツ)配達パートナーと大きく違う点は、1件の配達単価が固定であること。
これにインセンティブ(追加報酬)を加えることで、1件の配達で最大¥1,001をの報酬・給料を受け取ることができ、中には時給換算で¥5,000を超える配達員もいるそうです。
他にも、
- 注文品を受け取る前に、配達先がわかる
- 差配制度により、複数件同時に依頼を受けることができる
- 配達エリアが決まっているので、長距離配達がない
といった、特徴があります。
もちろん、配達員として工夫を重ねる必要はありますが、個人的にUber Eats(ウーバーイーツ)に比べて出前館配達員の方が安定した収入を得ることができるイメージがあります。
より詳細に出前館配達員とUber Eats(ウーバーイーツ)配達パートナーの比較について知りたい方は、下記のページで詳しくUber Eats(ウーバーイーツ)と出前館配達員の比較をしています。
Uber Eats(ウーバーイーツ)配達パートナーと出前館配達員はどちらが稼げるのか?
出前館配達員の登録はこちらから
- 時給2,000円を超えることは、可能!
- 平均時給2,000円は難しい!
- 安定して稼ぐなら、「出前館」がおすすめ!
【追記】出前館の配達アプリが2022年8月1日から大型リニューアル

こんな魅力的な出前館業務委託配達員ですが、実は2022年8月1日から全国エリアにおいて、配達アプリのリニューアル&配達報酬制度の改定が行われました!
今回は、あまり詳しくは解説しませんが、先ほどの解説内容との変更点に絞って、簡単に説明します。
- 配達距離によって変動する「距離報酬」が新しく追加され、固定報酬ではなくなった
- 距離報酬の対象になるのは「ドロップ距離(お店から注文者までの移動距離)」のみ
- 今までの報酬制度と比較すると、配達距離が2km未満の注文は単価が安く、2km以上の注文は高くなる
- 首都圏(一都三県)とその他エリアで設定が異なる
- 自動個別配車システムが導入されることで、複数件同時配達ができなくなった
今までは、配達距離にかかわらず、1件当たり○○円という固定報酬でしたが、出前館にも「距離報酬」の概念が加わり、配達距離に応じて、報酬・給料が変動するようになりました。
また、注文の受け方も従来の早押し制から「自動個別配車システム」という、現在地などの状況にあわせて、自動的に案件が振り分けられるようになりました。
これによって、複数案件の同時配達はできないようになりました。今までとかなり給料が変わる人がでてきそうです。
<変更後の配達報酬一覧>
| お店から配達先までの距離 | 距離別委託料 (東京・神奈川・千葉・埼玉) |
距離別委託料 (それ以外の道府県) |
|---|---|---|
| 1km未満 | 600円(税込) | 550円(税込) |
| 1km以上~2km未満 | 660円(税込) | 600円(税込) |
| 2km以上~3km未満 | 750円(税込) | 670円(税込) |
| 3km以上 | 870円(税込) | 770円(税込) |
これ以外にもいろいろな変化があった出前館ですが、稼げなくなったわけでは決してありません。
むしろ、配達員が働きやすくなった変更もたくさんあるので、興味のある方、給料を案敵的にアップさせたい方は、ぜひUber Eats(ウーバーイーツ)だけでなく、出前館の業務委託配達員にも登録してみてください。
出前館配達員の登録はこちらから
Uber Eats(ウーバーイーツ)配達パートナーで稼ぐコツ7選【給料UP】

冒頭でも触れたように、「時給2,000円以上を目指したい」「今よりも収入・給料をアップさせたい」なら、ただやみくもに配達するだけでは不十分です。
もちろん、毎日朝から晩まで働き続ければ、給料は上がるかもしれませんが、それは非効率すぎます。下手すると、時給換算したら普通のアルバイト以下なんてことも…
ここでは、時給UP!給料UP!を目指し、稼げる配達員がやっている“稼ぐコツ”を7つご紹介します。
① 雨の日に配達する
雨などの天気が悪い日は、高時給・給料UPを狙うチャンスです。
雨の日などの天気が悪い日は、配達員の数が減る一方、逆に配達依頼は増えます。雨の日はみんな、できる限り家から出たくないですよね。
ですが、稼ぎたいUber Eats(ウーバーイーツ)配達パートナーにとっては、大チャンス!いつも以上に多くの依頼を、少ない人数でこなすことができるので、回転率もぐんと上がります!
加えて、Uber Eats(ウーバーイーツ)配達パートナーの需要が高まることで、インセンティブ(追加報酬)も発生しやすくなります!
さらに、ピーク料金※が普段の倍近く上がるので、1件あたりの配達単価が上がり、給料・時給も大きく上がるでしょう。(※配達依頼が多くなる昼・夕方の時間帯に発生するインセンティブのこと)
雨の日は、稼ぎたいUber Eats(ウーバーイーツ)配達パートナーによって、かなりの好条件がそろっています!
| 通常 | 雨の日 | |
| 配達員の数 | 多い | 少ない |
| 配達依頼の数 | 普通〜少ない | 多い |
| クエストの発生率 | 低 | 高 |
| チップ | 低 | 高 |
| ピーク料金 | ¥100〜¥200 | ¥200〜¥400 |
ただし、悪天候時の配達は、危険度や負担も上がります。雨具など、事前準備は念入りに行い、当日は無理のない範囲で働くようにしましょう。
また、配達を始めたばかりの方にはトラブルも多く、特に負担がかかりますので、あまりおすすめしません。
いくら「給料がUPする!」といっても、ケガをしてしまっては元も子もありません。
あえて雨の日を狙っての配達は、ある程度配達経験を重ねてから行うと良いでしょう!
② ピーク時間内に稼働する
Uber Eats(ウーバーイーツ)では、配達依頼が1番多く入る時間帯を「ピーク時間」と言います。
ピーク時間は下記の通りです。
- ランチ :11:00 〜 14:00
- ディナー:18:00 〜 21:00
この時間帯は、飲食店が混雑する時間でもあり、他の時間帯に比べ配達依頼が多くなる時間帯でもあるので、高時給を狙うチャンスです。
副業で配達員をしている方は、長時間稼働するのが難しい場合もあるので、このピーク時間内に限定して、数時間働くことができれば、上手く稼ぐことができるでしょう。
また、専業配達員の方は、自分の食事時間をずらしてでも、このピーク時間には稼働するようにしましょう。
給料UPのためには、時には我慢も必要です!
③ ピーク・ブーストエリア内で稼働する
ピーク・ブースト報酬エリアの内と外では、1件あたりの単価が変わってきます。
1件あたりの報酬の差は数百円ほどですが、配達件数が増えるほど給料 / 収入の差は大きくなります。
かかる労力は全く変わりませんので、どうせ稼働するのなら、できるだけピーク・ブーストエリア内で配達し、給料UPを狙うのがおすすめです。
もし、ピーク・ブーストエリアの外へ飛ばされた場合は、一旦オフラインにして、エリア内へ戻った方が良いでしょう。
また、ピーク・ブースト報酬が発生するエリアは、駅前などの繁華街がほとんどです。
住宅街や地方などで配達されている方は、可能であれば稼働エリアを変えてみるのも良いでしょう。
少し面倒かもしれませんが、「稼ぎやすいエリアに移動してから稼働する」という発想も、給料UPのためにはとても大切な考え方ですよ。
④ 目標設定とモチベーションの維持
晴れて配達員デビューとなり、「よしやるぞ!」と意気込んでいたはずなのに、配達を続けていくうちに段々と稼働時間が減っていき、いつのまにか配達アプリはオフラインのままフェードアウト・・・。
Uber Eats(ウーバーイーツ)配達パートナーで高時給・高収入を得るには、「続けること」も大切です。
そのためにも、稼ぎたい給料や時給を設定し、モチベーションを高く保つための工夫をしておくことはとても重要だと考えます。
Uber Eats(ウーバーイーツ)配達パートナーの仕事は、良くも悪くも個人プレイです。
ノルマもシフトもないので、サボろうと思えばいつでもサボれてしまいますからね。
「自分に甘い方かも…」そんな自覚のある人は、とくに注意してください!
1.「給料はいくら欲しいのか?」目標を設定する
月にどれくらい給料 / 収入が欲しいのかを決め、それに合わせて1週間 ⇒ 1日 ⇒ 1時間あたり(時給換算)の稼ぎたい目標金額を設定してみましょう!(いきなりは難しい!と感じる方は、最初はなんとな~くの金額でもOKです)
金額を設定する際は、配達する地域の平均時給や最低賃金を参考にすると良いでしょう。
例えば、
- 配達する地域の、Uber Eats(ウーバーイーツ)の平均配達単価が450円
- 地域の最低時給が850円/1h、平均時給が1,000円/1h
だった場合でみてみましょう。
この地域で、1時間以内に2件配達できれば最低時給以上、3件配達できれば、一般的なアルバイトよりも稼げている、ということになります。
さらに、4件以上配達することができれば、一般的なアルバイトよりも大幅に稼げるということになります。
Uber Eats(ウーバーイーツ)の給料は、ばらつきがでて当然
ただし、Uber Eats(ウーバーイーツ)配達パートナーは、天気や時間帯などにより、給料・時給に”ばらつき”が出ます。
時給で働くアルバイトととは違い、あくまでも時給換算なので、仕方がありません。
そんなときは
- 「昼間は3件、注文が増える夜は4件を目安に配達しよう」
- 「明日は雨だから、いつもより少し多めに稼働して稼いでおこう」
といった具合に、経験を重ねながら機転を利かせて配達していくと良いでしょう。
1日の目標件数絶対死守!というよりは、状況にあわせて臨機応変に配達する法が、給料UPにつながります。
また、あまり目標を高く設定しすぎてしまうと、達成できなかった場合にモチベーションが下がる原因にもなります。
まずは、確実に達成できる件数から目標設定するのが良いでしょう。
小さくても、コツコツと目標達成の喜び・成功体験を積み重ねていくことが、長く稼ぎ続けるポイントです!
2.モチベーションを維持する
Uber Eats(ウーバーイーツ)配達パートナーを続けるために、モチベーションを高く保つための工夫をしましょう。
具体的には、配達で使うものなどにちょっとしたこだわりや工夫をすると良いでしょう。
例を挙げると、下記のとおりです。
- 自転車にスマホ / ドリンクホルダーをつける
- 荷物が重いので、荷台 / 宅配ボックスをつける
- 雨の日に使う雨具は機能性の高いものを使う
- 冬は防寒用にハンドルカバーを取り付ける
- お気に入りのスニーカーを履いていく
配達を続けていくと
「これがあったら便利だな / テンション上がるな」
「これがあればもっと効率よく配達できそう」
という気づきや感想が出てくるので、都度工夫することで、楽しく配達できる環境を作っていきましょう。
「お金がかかってしまう…」と思うかもしれませんが、自分への先行投資はある程度必要です。
配達をこなしていくなかで、徐々に修正していくと良いでしょう♪
備品を購入した場合は、必ず領収書を保管すること
また、少し話は変わりますが、配達に必要な備品を購入した場合は、年度末の確定申告の際、「経費」として申請することができますので、領収書は必ず保管しておきましょう!
給料をあげることも大切ですが、こういう税金対策も忘れずに、しっかり行っていきましょう。
⑤ マイルールを決めておく
効率的な配達を行うために、状況に応じたマイルールを決めておきましょう。
マイルールの例は、以下の通りです。
- ピーク時、お店の料理の待ち時間は5分まで。
- オフピーク時の待ち時間は、最大10分まで。
- ピーク時の配達依頼は、大手チェーン店の注文のみに絞る。
- ピーク時の配達依頼は、クレジット決済のみの注文に絞る。
ピーク時は注文数が増え、稼ぐチャンスです。
1件でも多くの依頼をこなすために、配達にかかる時間をできる限り短縮させることが給料UPにはとても大切です。
大手チェーン店は店舗数が多いので、配達距離が短い依頼が比較的多いです。また、注文依頼も多いので短時間で多くの配達をこなせる可能性が高くなります。
さらに、クレジット決済のみの注文に絞ることで、現金の受け渡しの必要がなくなるのでお客様とのやり取りが少なく済み、結果、配達時間の短縮に繋がります。
ただし、注文依頼が少なくなる時間帯は、現金対応も可能にしておくことで配達件数を稼ぐことができるでしょう。
とにかく、無駄な時間を減らし、減らした時間で1件でも多く件数をこなすことが、時給UP・給料UPには欠かせない考え方です!
⑥ 配達時間を短縮させる
給料・時給を上げるためには、多くの配達をこなす必要があります。
配達件数を増やすには、1件あたりの配達時間を短くすることが一番効果的です。
ここでは、配達時間を短くし、給料をUPさせる具体的な方法を2つご紹介します。
1.場所を確認する時間をできる限り減らす
Uber Eats(ウーバーイーツ)の配達パートナーは、配達中Google Mapなどを使い、お店の場所や配達先を確認することになります。
この時、確認する回数が増えるほど、タイムロスが増えるため、結果的に1回あたりの配達時間が長くなってしまいます。ピーク時間など、配達依頼が多くなる時ほど、このタイムロスはボディーブローのようにジワジワと効いてきます。
効率よく、素早く配達をこなすためにも、なるべく配達エリアの地形と住所は覚えるようにしましょう。
配達し始めの頃は大変ですが、「一度通った道は忘れないでおこう!」と意識しながら配達をこなすことで、回数をこなしていくと自然と覚えることができます。
ただし、あまり無理をする(分からないのに地図を見ず、勘で移動する)とかえって配達に時間がかかってしまい、到着が遅れたり、配達先を間違えると余計なクレームにもつながってしまいますので、少しずつできる範囲で進めていきましょう。
ベテラン配達員の中には、住所を見た瞬間に配達先までのルートが浮かぶくらい地図を読み込んでいる方もいます。
2.止まらずに進むための“抜け道”を覚える
配達時、時間を取られる大きな要因の1つとして「信号待ち」が挙げられます。
これは、自転車でも、バイクでも同じことです。
大通りの信号になると、2 ~ 3分ほど待たされる信号もあるのではないでしょうか?
Uber Eats(ウーバーイーツ)で高収入を得ている配達員の中には、赤信号や通行止めなどの場合に、止まらず進むための“抜け道”を把握している方が多くいらっしゃいます。
1件あたりの配達時間を減らし、少しでも多くの配達をこなすために、日頃から地図を読み込むことで、できる限り多くの”抜け道”を把握しておくと良いでしょう。
とくに、自転車で配達する人は、バイクや車よりも移動できる選択肢が多いので、日ごろから意識的に抜け道を探す癖をつけましょう。
⑦ ママチャリは使わない
ママチャリは速度が遅く、疲労がたまりやすいので、配達件数が下がる要因になりやすいです。
自転車で配達するなら、クロスバイクやロードバイクなどの軽い自転車の方が速度も出しやすく、疲労も溜まりにくいのでおすすめです。
ある程度勾配がある地域で配達されている方は、電動自転車も良いでしょう。
以上が、Uber Eats(ウーバーイーツ)配達パートナーで稼ぐコツ7選です。
- 雨の日に配達する
- ピーク時間内に稼働する
- ピーク・ブーストエリア内で稼働する
- 目標を設定し、モチベーションを高く保つ
- マイルールを決めておく
- 配達時間を短縮する
- ママチャリは使用しない
【おまけ1】Uber Eats(ウーバーイーツ)稼いでいる人発見!
実際に、稼げている人のツイートを一部抜粋しました!
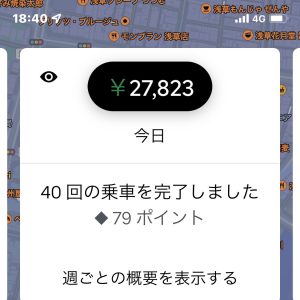
(引用元)
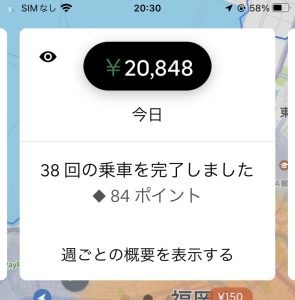
(引用元)

(引用元)
稼ぐコツさえつかめれば、これから始める人でも、決して不可能な数字ではありませんよ!!
【おまけ2】自転車とオートバイどっちが稼げるか?
一つおまけで解説しておきます。
Uber Eats(ウーバーイーツ)では、自転車とオートバイどっちが稼げるのか?とよく聞かれます。
この答えは、配達するエリアによっても変わるのですが、基本的には“自転車”の方が稼げることが多いと言われています。
オートバイで配達するメリットは、体力負担が少なく、長距離の配達依頼を受けやすく、1件あたりの配達単価は高くなる点があげられますが
- 1件の配達に時間がかかることが多い
- 燃料代やメンテナンス、税金などの維持するためのコストがかかる
- 交通違反により罰則金を払わされる可能性がある
など、自転車に比べてデメリットが多いのも事実です。
しかし、オートバイ(原付)で高時給・高収入を得ている配達員もたくさんいますので、結果としては、実際に両方の手段で配達してみて、“自分が気に入った方で配達する”で問題ないでしょう。
Uber Eats(ウーバーイーツ)では、途中で配達車両を変更するもできます!
もう一つ、稼ぐコツとしてあげるとすれば、「チップ制度」をうまく利用するのも1つの手かもしれません。
チップ制度とは、注文者が、注文金額の5% ~ 20%、または任意の金額を配達員に直接支払うことができるシステムです。
詳しくは、この後の見出しにて説明していますので、気になる方は是非ご覧ください。
Uber Eats(ウーバーイーツ)の登録はこちらから
>>Uber Eats(ウーバーイーツ)配達パートナー公式登録ページ
Uber Eats(ウーバーイーツ)配達パートナーの報酬(給料)の仕組み
Uber Eats(ウーバーイーツ)配達パートナーの報酬(給料)は、
(基本料金 ー 手数料) + インセンティブ = 報酬
という形で決定されます。
ここでは、配達員がもらう報酬(給料)は具体的に、どのような形で計算され、決定しているのかについて解説していきます。
※追記※
2022年8月現在のUber Eats(ウーバーイーツ)配達パートナーの報酬制度は、2021年5月10日に改定されたものです。
それ以前の配達報酬の仕組みから変更されている部分も多いので、修正・追記しながら解説していきます。
配達報酬 = 配送料(基本金額 + 配達調整金額)- サービス手数料 + インセンティブ
一番大きな変更点として、まず覚えておいてほしいことは、「配達報酬の計算方法などの詳細がブラックボックス化し、Uber Eats(ウーバーイーツ)公式からの発表がなくなった」ということです。
まだ「?」だらけだと思いますが、詳しく見ていきましょう。
基本料金⇒「配送料」と「サービス手数料」

基本料金は、
受取料金:お店で商品を受取った際にもらえる報酬受渡料金:配達が完了した際にもらえる報酬距離料金:お店から配達先までの距離に応じた報酬
の3つで構成されています。
※追記※
早速、情報を更新していきます。
Uber Eats(ウーバーイーツ)の配送料は、「基本金額」と「配達調整金額」によって構成されています。
それぞれ具体的に何を指しているのか、またどう変わったのか、見ていきましょう。
「基本金額」とは?
Uber Eats(ウーバーイーツ)の配送料の一番ベースとなるのが、この「基本金額」です。
※以前の報酬制度でいうと「受取料金」「受渡料金」「距離料金」がこれにあたります。
当時は、この基本金額にあたる報酬額が、配達エリアによって明確に定められており、私たちUber Eats(ウーバーイーツ)配達パートナーも、自分で計算することができました。
しかし、残念なことに、現在の報酬体系においては、基本金額の算出方法が公表されていません。
「1回配達したら報酬○○円」や「何km移動したから給料○○円」といった基準が、Uber Eats(ウーバーイーツ)公式から一切発表されていないのです…
報酬体系が変更された当時は、報酬単価が下がったこともあり、「改悪だ!」「給料が下がった!」と、業界ではかなり話題になりました。
Uber Eats(ウーバーイーツ)公式によると基本金額は、「配達にかかる時間と距離」、また「商品の受取場所や配送先が複数あるかどうか」に応じて、自動的に算出されています。
※ここでいう「配達にかかる時間・距離」とは、以前は「飲食店から注文者まで」のことを指しましたが、現制度では、「注文を受けた場所からお店まで」が報酬(給料)に反映されるようになっています。
基本金額は、ざっくりとした目安しかお伝え出来ませんが、およそ300円~400円前後での場合が多くなっています。
配送料(配達調整金額)
配送料を構成するもう一つの項目が「配達調整金額」です。
これは、昔の報酬体系にはなかった、新しい考え方です。
「配達調整金」とは、下記のような状況下で配達をした時に、基本金額に加算される配送料のことを指します。
- 通常よりも交通状況が混雑している時
- お店に到着した時、まだ料理ができておらず、商品受け取りまでに時間がかかった場合
- 他に稼働している配達員が少なく、通常よりも配達の需要が高い場合
つまり、配達員には一切の落ち度はないが、致し方のない事情で配達が進められなかったとき、想定以上に時間が買った場合などに、調整金がもらえるようになっています。
嬉しい変更点なのかもしれませんが、残念ながら、この配達調整金の詳細の内訳や算出方法も非公表となっています。明確な基準は不明です…
配達調整金は、およそ100~200円程度のことが多くなります。
受取料金(固定)
注文先のお店で商品を受け取った際に発生する料金です。
配達先が2箇所ある”同時配達”の場合は、受取料金は1回分しか発生しないので注意が必要です。
受取料金は固定料金ですが、配達エリアによって料金が異なります。
受渡料金(固定)
注文者に商品を渡した際に発生する料金です。
同時配達の場合は、1件ごとに受渡し料金が発生します。
受渡料金は固定料金ですが、配達エリアによって料金が異なります。
距離料金(変動)
お店から配達先までの距離に応じて、1㎞ごとに計算されます。
同時配達の場合は、合計の距離で計算されます。
”注文先のお店までの距離”は料金に含まれないことに注意が必要です。なるべく短時間で受け取りに行けるよう日頃から工夫しましょう。具体的には、
配達エリアの時間帯ごとの注文傾向を把握する大手チェーン店など、注文が多く入るお店の近くで配達するなど、配達をこなしながら、効率よく無駄のない配達になるよう改善していきましょう。ピーク時に”お店までの距離が長い”依頼が来た場合は、キャンセルするのも1つの手です。
サービス手数料
サービス手数料は、基本料金から“決められた割合に応じて”差し引かれる料金になります。
割合(%)は配達エリアによって異なります。
※追記※
サービス手数料については、配達エリアによる違いがなくなり、全国一律で「基本金額の10%」が引かれることになっています。
また、インセンティブ(追加報酬)にサービス手数料がかかることはない点は、変更ありません。
【一覧】配達エリアごとの基本料金とサービス手数料
※追記※
こちらの表については、今は使われなくなっていますので、参考程度にご覧ください。
配達エリアごとの基本料金とサービス手数料をまとめました。
ご自身が稼働されるエリアを確認しておくと良いでしょう。
エリア 都道府県 受取料金 受渡料金 距離料金 サービス手数料
関東 埼玉県 300円 170円 150円/km 35%
千葉県 300円 170円 150円/km 35%
東京都 265円 125円 60円/km 10%
神奈川県 250円 120円 60円/km 10%
中部 愛知県 215円 105円 60円/km 10%
九州 福岡県 215円 105円 60円/km 10%
近畿 京都府 215円 105円 60円/km 10%
大阪府 215円 105円 60円/km 10%
兵庫県 215円 105円 60円/km 10%
こんな感じで、表にできていた時代が懐かしいな…給料の計算がととても簡単だ…
インセンティブ(追加報酬)
.png)
インセンティブとは、Uber Eats(ウーバーイーツ)で稼ぐためには絶対に欠かせない「追加報酬」のことです。
Uber Eats(ウーバーイーツ)のインセンティブには
- ブースト
- ピーク料金
- クエスト
- チップ
の4種類があります。
インセンティブによる報酬金は、配達エリアや時間帯、配達パートナーのレベルなど、さまざまな要因によって変化します。
インセンティブを上手く活用することで、より高時給(給料)を狙うことができるため、しっかりと把握しておくようにしましょう!
①ブースト
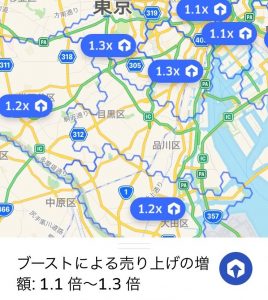
ブーストとは、注文が集中する時間帯に、その配達エリア内の基本料金に1.1倍〜1.4倍ほど※の倍率を掛けて、報酬金額を増やす仕組みのことです。(※配達エリアや時期によって、倍率は変動します。)
ブーストが発生している場所で配達をすることで、より高時給(給料)を得ることができます。
具体的に、どのくらい給料が上がるのが、例をあげて確認してみましょう。
- 基本金額:500円(サービス手数料差し引き前の金額)
- ブースト:1.2倍
の場合は、ブーストが適応されると、500円 × 1.2 = 600円 となり、通常よりも100円多く、追加給料を得られるようになります。
※ブースト報酬には、サービス手数料は適用されません。
1件あたりで見ると大した金額ではないかもしれませんが、配達件数をこなせばこなすほど大きな差が出てくるので、できる限りブーストが発生しているエリアで配達することをおすすめします。
ブースト「アリ / ナシ」でそれぞれの時給・給料を比較してみましょう♪
「1日3時間 / 週5日」で1ヶ月続けた場合を例にすると、
- 1時間の配達件数が3件
- 1件あたりの配達単価を500円
- ブースト倍率1.2倍
とした場合、
- ブーストアリ:時給1,800円 / 月収108,000円
- ブーストナシ:時給1,500円 / 月収90,000円(※1ヶ月=4週間で計算)
となり、給料の差額は18,000円となりました!
これを見ると、ブーストは高時給(給料)を達成するための重要なポイントであることが分かりますね♪
2021年5月10日に改定されたUber Eats(ウーバーイーツ)の報酬制度の影響で、実はブースト報酬にも変化が起きています。
結論から言うと、Uber Eats(ウーバーイーツ)の報酬制度変更後、ブースト報酬は下がりました。
以前までは、「距離報酬+受取報酬+受渡報酬」にブースト倍率がかかっていましたが、現在は“配達調整金額を含めない”基本金額にのみ、倍率をかけて報酬を計算します。
そのため、
- 基本金額が300円
- 配達調整金額が200円
- ブースト倍率が1.2倍
だった場合、ブーストの倍率は300円にしかかからないため、ブースト報酬は、60円しか獲得できなくなってしまいました。
(以前は500円に1.2倍のブースト倍率がかかっていたため、ブースト報酬は100円でした。)
給料をあげたい!と思っている我々配達院からすると、残念ですね…
②ピーク料金
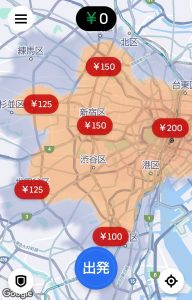
ピーク料金は、配達員が不足しているエリアで発生するインセンティブです。
ピーク料金が発生しているエリアは、ヒートマップで表示されるので、視覚的に「給料を稼げるエリア」が分かります。
具体的には、雨の日や注文が集中するピークタイム時に、対象のエリアがオレンジ~赤で滲んだように表示されます。
ヒートマップ内に表示されている金額が、配達完了時に追加で獲得できます。
ピーク料金はブーストと合わせて、高時給・給料UPを達成するための重要なポイントになるので、発生していた場合はできる限りそのエリア内で配達しましょう。
個人的に、繁華街エリアには、毎回「ブースト」か「ピーク料金」のどちらかのインセンティブは発生している印象があります!
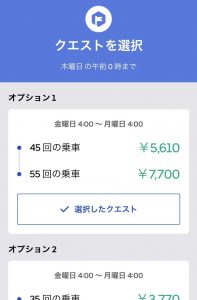
③クエスト
クエストは、配達回数に応じて追加で支払われるインセンティブです。
クエストには、
- 日跨ぎ(ひまたぎ)クエスト
- 週末クエスト
- 悪天候クエスト
の3種類があります。
それぞれのクエストについて、解説していきます。
■日跨ぎ(ひまたぎ)クエスト
ほとんどの配達員が使っている、最も基本的なクエストです。
指定された期間内に目標件数分の配達を達成すると報酬が加算される仕組みです。
- 週2回(月〜木 / 金〜日)発生する
- 複数のクエストから自分に合ったものを選択できる
- クエストの選択には締め切り時間がある
- 目標件数や報酬金額は配達員によって異なる
日跨ぎクエストは、複数用意されていて、どれか1つを選択することができます。
自分の稼働予定と照らし合わせて、確実に達成できるクエストを選択しましょう。
また、日跨ぎクエストは選択に締め切り時間があるので忘れず選択するようにしましょう。
Uber Eats(ウーバーイーツ)では、一定期間稼働しなくなると、目標件数と報酬額が下がったり、そもそもクエストが発生しなくなることもあるので注意が必要です。
■週末クエスト
土日、または祝日限定で発生するクエストです。
不定期で発生しますが、最近はあまり見かけなくなりました。
指定時間内に指定回数分の配達を達成することで、追加報酬を得ることができます。
週末クエストは、当日中に達成させるクエストで、内容は地域によって異なります。
■悪天候クエスト
雨の日など、天気が悪い日に発生するクエストです。
指定時間内に指定回数分の配達を達成することで、追加報酬を得ることができます。
※追記※クエストにも変更点あり!
実は、2021年の12月20日に行われたUber Eats(ウーバーイーツ)の給料改訂によって、クエストの内容も大幅に改訂されています。
以前までは、一部エリア(仙台・東京・横浜・京都・大阪・神戸・福岡・岡山・広島)に限り、自分でクエストを選択できる仕様でしたが、現在は撤廃されています。
基本的なクエストの仕組みに変更はないのですが、Uber Eats(ウーバーイーツ)側が配達員ごとにクエストを自動的に振り分けるようになりました。(※この振り分け方の基準も分かっていません…)
④チップ
チップは、注文金額の5% ~ 20%、または任意の金額を配達員に直接支払うことができるシステムです。
素早く手際の良い配達や丁寧な対応など、配達の質が高ければチップをもらえる確率は上がるでしょう。
タワーマンションに住む富裕層の方やチップ文化に慣れている外国の方からよくいただく、なんて話も聞きます。さらには、注文先のお店の方から直接いただいた、という話もあるそうです。
一般的なアルバイトでチップをいただくことは滅多に無いことで、いただいたときは本当に嬉しい気持ちになります!
モチベーションアップにも繋がる、個人的にも良いシステムだと思います。
少しでも給料を底上げしたい方は、「どうすればチップをもらえるか?」言い換えると、「自分がお客さんだったら、どんな人にならチップをあげてもいいかなと思うか?」を考えてみるとよいかもしれません。
チップ制度は、Uber Eats(ウーバーイーツ)配達パートナーをやる上での魅力の1つになるでしょう。
お釣りをチップとして、くれる方もいらっしゃるそうです。
そういうところを見ると、現金対応可で依頼を受け付けるのも”アリ”かもしれませんね。
オンライン時間インセンティブは、分かりやすく言うと時給保証になります。
指定された時間内で報酬金額が一定額に満たなかった場合、その差額を支払ってもらえる仕組みです。
例えば、1時間1,000円のオンライン時間インセンティブが適用されていた場合、その時間の時給が800円※だった時は、200円を追加で受け取ることができます。(※基本料金からサービス手数料を差し引いた金額。)
新規エリアで発生する印象があり、既存のエリアでは、ほぼ発生しないと考えて良いでしょう。
- 配達報酬 = 配送料(基本金額 + 配達調整金額)- サービス手数料 + インセンティブ
- インセンティブ = (ブースト / ピーク料金 / クエスト / チップ)
Uber Eats(ウーバーイーツ)の配達エリア
Uber Eats(ウーバーイーツ)は、2021年9月28日(火)から、日本全国47都道府県で利用可能になりました!
つまり、Uber Eats(ウーバーイーツ)の配達エリアは、日本中にあります。
Uber Eats(ウーバーイーツ)のサービスが日本で開始して以来、利用可能なエリアは、毎年毎月増え続けているので、今後もますます拡大していくことが期待できます。
現在配達可能なエリア、つまり稼働できるエリアは、Uber Eats(ウーバーイーツ)公式サイトにてご確認ください。
全47都道府県で稼働できるとはいえ、対象となる配達可能なエリアは、一部エリアのみですので、気を付けてください!
Uber Eats(ウーバーイーツ)配達パートナーのメリット

ここまで、Uber Eats(ウーバーイーツ)配達パートナーの報酬・給料・収入・時給など、お金にまつわる情報を中心に解説してきましたが、Uber Eats(ウーバーイーツ)のメリット・良い点は、「稼ぎ」以外にもいくつもあります。
せっかくなので、Uber Eats(ウーバーイーツ)のメリットについても、改めてここでまとめておきましょう。
一般的なアルバイトよりも稼ぎやすい
上で見たように、一般的なアルバイトの時給と比べて400〜500円ほど多く稼ぐことができるのは、Uber Eats(ウーバーイーツ)配達パートナーをやる上での大きなメリットです。
天候や時間帯によって、あまり給料 / 時給が上がらない日もありますが、総合して見るとアルバイトよりも多く稼ぐことができるでしょう。
また、経験を重ねてより多くの配達をこなすことができれば、その分多くの収入・給料を得ることできます。
結果を出せば出すほど、より高時給・高収入を得ることができるのも、Uber Eats(ウーバーイーツ)配達パートナーやる上での大きなメリットです。
頑張れば頑張っただけ給料が上がっていくのが、成果報酬制の魅力ですね!
ライフスタイルに合わせて、自由に働ける
- 本業で朝〜夜までがっつり!
- 副業として、空き時間に少しだけ…
- 今月は、もう少し稼ぎが欲しいのでちょっとだけ…
- 買いたいものがあるので短期集中で!
など、Uber Eats(ウーバーイーツ)配達パートナーは、ライフスタイルや目的に合わせて、好きな時間に働くことができます。
専用アプリを起動することで、8:00 〜 25:00※の好きな時間で働くことが可能です。(※地域によって営業時間が異なる場合があります。)
「今日は、雨だからやめておこう〜」
「ちょっと眠いから、午後からにしよう…」
なんてこともできます(笑)良いか悪いかは別としてですが。
しかし、自由に働けるということは裏を返せば、その分“仕事で生じた問題や責任は、全て自分が負担しなければならない”ということにもなるので注意が必要です。
会社に勤めている方の中で、
「会社には内緒で、Uber Eats(ウーバーイーツ)で副業がしたい…」
という方もいらっしゃるのではないでしょうか?
Uber Eats(ウーバーイーツ)配達パートナーは、稼いだお金をご自身で税務署、市区町村の役所へ申告する(所得税の納付方法を「特別徴収」ではなく、「普通徴収」にする)ことで、会社には内緒で副業をすることができます。
ただし、申告の際は住民税をご自身で納付する※必要があるので注意が必要です。
(※自身で納付しなかった場合、会社の給料から天引きされることになり、副業がバレる原因になります。)
報酬が週払い制
Uber Eats(ウーバーイーツ)配達パートナーの給料は、毎週支払われます。つまり、毎週給料日がある感じです!
具体的には、毎週月曜日〜日曜日までの収入が、2日後の翌週火曜日に支払われます。(※月曜日が祝日の場合は水曜日になります。)
来週末までにお給料が欲しいときに、配達して稼ぐ、ということも可能です♪
>>Uber Eats(ウーバーイーツ)配達パートナー公式登録ページ
職場のストレスから解放される
Uber Eats(ウーバーイーツ)配達パートナーは、個人で好きな時間に働くことができます。
毎朝、満員電車に乗る必要もなく、売上のノルマ等もありません。
嫌な上司や取引先もいなければ、残業もシフトもありません。
- 人とのコミュニケーションがあまり好きではない方
- 自分で目標を設定し、自由に働きたい方
- でも、たくさんの給料を稼ぎたい!
このような方に、Uber Eats(ウーバーイーツ)配達パートナーはおすすめです。
職場のさまざなストレスに振り回されることなく、のびのびと仕事をすることができるのが、Uber Eats(ウーバーイーツ)配達パートナーの大きなメリットです。
服装や髪型は自由
会社員や一般的なアルバイトでは、服装や髪型などに制限があることが多いです。
Uber Eats(ウーバーイーツ)配達パートナーの服装や髪型は、自由です。
ただし、あまりにも派手な格好や、清潔感のない不潔な服装をしていると、配達員として低評価をもらう場合があるので注意が必要です。
最低限、食料品を扱う自覚は必須ですね。
痩せる(自転車の場合)
実は個人的には、これが1番嬉しいメリットだったりします(笑)
自転車を使う場合に限りますが、Uber Eats(ウーバーイーツ)配達パートナーはかなりいい運動になります。
普段、運動不足で悩んでいる方やデスクワークで溜まったストレスを解消したい方は、運動目的で配達をされるのもいいかもしれません(笑)
給料ももらえて、体にもいいなんて!一石二鳥とはまさにこのこと!
- ライフスタイルに合わせて自由に働ける
- 報酬が週払い制
- 職場のストレスから解放される
- 服装や髪型は自由
- 自転車で配達すれば痩せる
Uber Eats(ウーバーイーツ)配達パートナーのデメリット

Uber Eats(ウーバーイーツ)配達パートナーの仕事、正直にいうと、メリットばかりなわけではありません。ある程度のデメリットも存在します。
「こんなデメリットがあるから、Uber Eats(ウーバーイーツ)で働くのは辞めろ!」というつもりは一切ないですが、Uber Eats(ウーバーイーツ)の実情を正しく理解しておくことはとても大切です。
天候や時間帯、配達エリアによって給料・時給にばらつきがある
雨の日やランチ・ディナータイムなどのピーク時間は注文数が増えるので、高時給を狙うことができます。
ですが、それ以外の場合は(配達地域にもよりますが)注文数が少なくなり、給料・時給が低くなりやすいです。
また、駅近くの繁華街エリアなどはブースト報酬が発生することが多いので、郊外のエリアに比べて給料・時給が高くなります。
同じ業務なのに給料が変わるのなら、少しでも高給料がもらえる条件下のエリアで稼働することを意識しましょう!
真夏 / 真冬、雨の日の配達がキツイ
- 7〜8月のジリジリと肌が焼けるような猛暑の中
- 12〜2月の身が切れるような寒さの中
このような状況で配達するのは、想像しただけでもキツイのがわかります…。最近の猛暑・酷暑は異常ですね…
ただし、これは他の配達員も条件は同じです。
つまり、何が言いたいかというと…
この時期は、稼働している配達員の数が減るので、いつもより多く配達依頼を受けることができる!ということです。
雨の日も同様で、いつもより配達がしにくい上に、ビショ濡れになるので配達員の数は、通常時よりもグンとが減ります。
このタイミングで稼働することによって、いつもより多く配達をこなすことができるでしょう。
さらに、雨の日はインセンティブ(追加報酬)が発生するので、高時給を得る、給料UPの大チャンスになります。
レッツ・ポジティブシンキング!
身体への負担も増えるので、くれぐれも無理のないようお気をつけください。とくに、初心者の方は注意が必要です。
道具を揃える必要がある
配達バッグをはじめとした、Uber Eats(ウーバーイーツ)配達パートナーで使用する道具は、全て自分で揃える必要があります。
- 配達バッグ
- スマホ
- スマホスタンド
- モバイルバッテリー(充電器)
- 充電ケーブル
- 防水ケース
- 雨具
- タオル
- 自転車・オートバイ
- 各種保険(必要に応じて)
最低限でもこれくらいは必要になります。
すでに持っているものを使うことで、コストを抑えることができますが、例えば、より高時給を狙うために新しくロードバイクやオートバイを買う場合などは、収入以上の出費で大赤字にならないよう注意が必要です。
なお、自転車やオートバイはレンタルサービスを使うのも1つの手でしょう。
ただし、「お金をかけたくない」と節約しすぎて、配達しにくくなってはいけません、配達のし辛さは、給料DAWNに直結します。
給料UPのためには、ある程度の自己投資は必要だと思っておいてください!
保証がない・自己責任
配達には自転車やオートバイを使用するため、事故に遭う / 起こすリスクがあります。
Uber Eats(ウーバーイーツ)配達パートナーは、会社員や一般的なアルバイトと違い、業務委託形式で仕事を行うことになります。
そのため、保険や労災などに自ら加入する必要があります。
自由性が高く、好きな時に働けるのがUber Eats(ウーバーイーツ)配達パートナーの大きな魅力ですが、裏を返せば、保証がなく、仕事に対する責任は全て自分が負う必要がある、ということでもあるので注意が必要です。
配達を始める前に、しっかりとチェックしておきましょう。
自転車保険などの、各種保険に加入する際は、「配達中の事故にも保険が適用されるもの」選んでください。
基本的に、通常の保険内容だと、「業務中の事故」は補償の対象外になってしまいますので、保険を選ぶときは、補償条件についても、しっかり把握しておきましょう。
確定申告が面倒
Uber Eats(ウーバーイーツ)配達パートナーの仕事で年間20万円以上の所得※がある場合、確定申告をする必要があります。
(※ 所得 = 売上 ー 経費 )
特に本業で配達員をされる方は、日頃から領収書の管理や記帳をする必要があります。
また、副業の場合は、普段は年末調整など、会社の総務・経理担当の人が手続きをしてくれるので、詳しく知らない方もいるかもしれません。
ただ、これを面倒だからと言って放置していると、後々税務署から通知がくるので注意が必要です。
費用はかかりますが、税理士に確定申告を依頼するのも1つの手でしょう。
- 時給にばらつきがある
- 真夏 / 真冬、雨の日の配達がキツイ
- 道具を揃える必要がある
- 保証がない・自己責任
- 確定申告が面倒
Uber Eats(ウーバーイーツ)配達パートナーの実際の収入例

ここでは、今回の記事を執筆するにあたり、参照した実際の報酬・給料のデータを記載します。
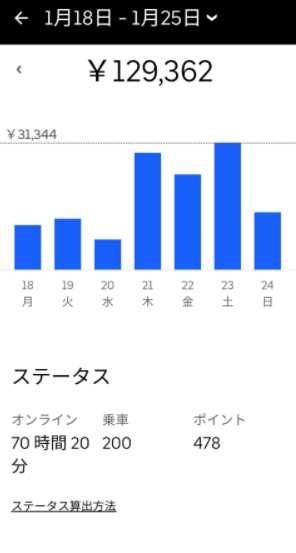
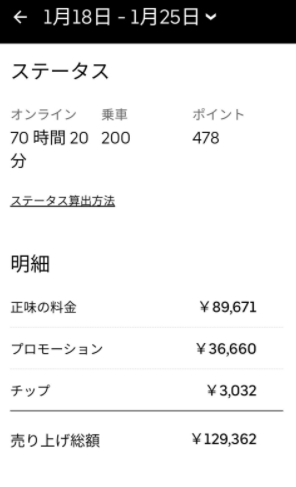
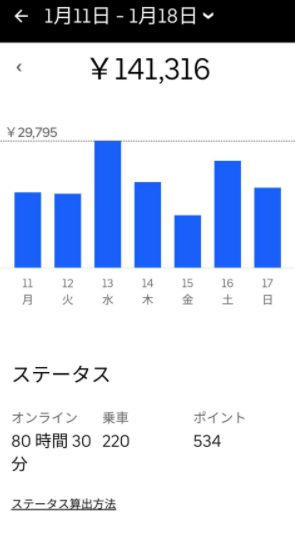
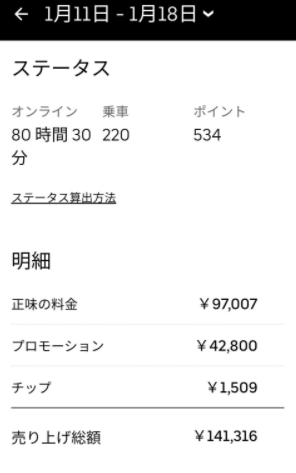
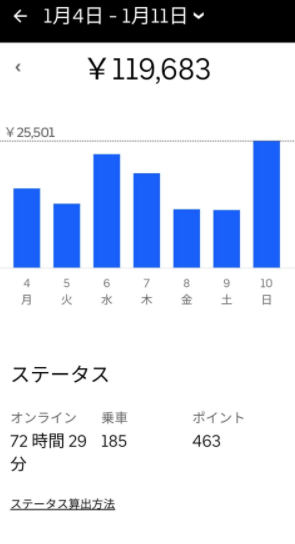
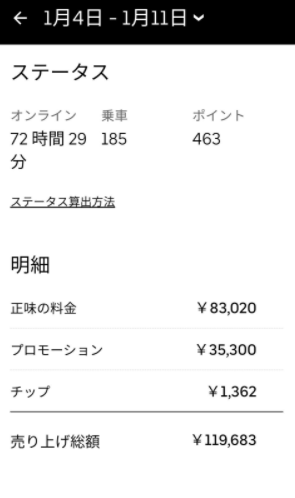
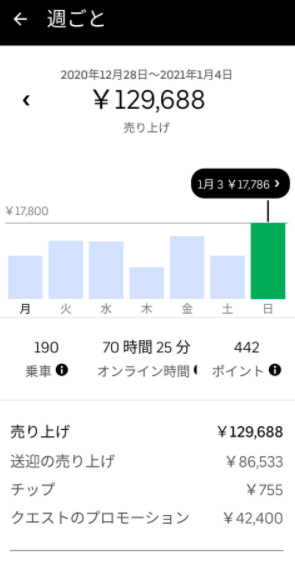
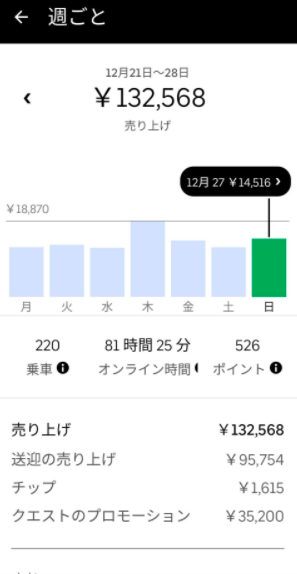
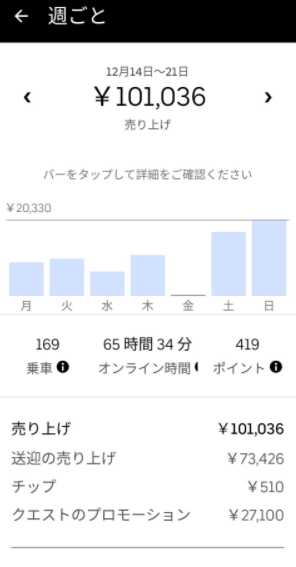
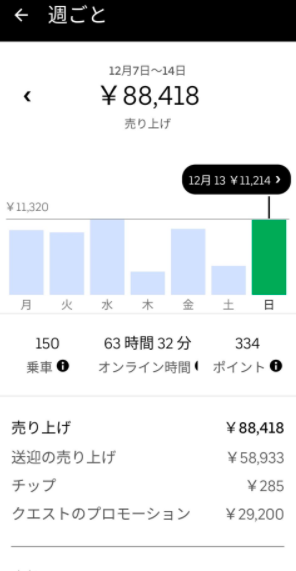
(引用:https://twitter.com/meitaro777)
>>Uber Eats(ウーバーイーツ)配達パートナー公式登録ページ
まとめ
ここまで読んでいただきありがとうございます。
- Uber Eats(ウーバーイーツ)配達パートナーの給料・時給(換算)
- Uber Eats(ウーバーイーツ)配達パートナーで稼ぐコツ
- Uber Eats(ウーバーイーツ)配達パートナーのメリット・デメリット
- Uber Eats(ウーバーイーツ)配達パートナーの報酬の仕組み
について、理解を深めていただけたでしょうか?
Uber Eats(ウーバーイーツ)配達パートナーで高時給を得るためには、とにかく継続することです。
そして、経験を重ねて作業を改善・効率化していくことで、短い時間で1件でも多く配達すること。これが給料UPには必須です。
こうして、あれこれ考えながら配達しているうちにいつの間にか、以前よりも給料・時給が上がっていることに気づくと思います。
配達エリアのニーズを考えたり、時間帯による消費傾向を掴んだり、作業の無駄をなくすにはどうすれば良いか?と改善していく“思考力”は、他の仕事にも活かせる大切な要素だと考えます。
この記事が皆さまの給料・時給アップに繋がれば幸いです。
ここまで読んでいただいた方の中で、また登録していないという方がいましたら、この機会にぜひ始めてみませんか?
>>Uber Eats(ウーバーイーツ)配達パートナー公式登録ページ
 【最高月収は?】Uber Eats(ウーバーイーツ)はいくら稼げる?給料の仕組みについても
出前館の業務委託配達員の報酬単価や多く稼げる理由について解説!
【最高月収は?】Uber Eats(ウーバーイーツ)はいくら稼げる?給料の仕組みについても
出前館の業務委託配達員の報酬単価や多く稼げる理由について解説!
 【出前館】業務委託配達員の報酬単価は?稼げる理由をまとめてみた!
Door Dash(ドアダッシュ)配達員の特徴やUber Eats(ウーバーイーツ)との違いについても解説!
【出前館】業務委託配達員の報酬単価は?稼げる理由をまとめてみた!
Door Dash(ドアダッシュ)配達員の特徴やUber Eats(ウーバーイーツ)との違いについても解説!
 Door Dash(ドアダッシュ)が日本進出!特徴は?Uber Eats(ウーバーイーツ)との違いについても
Door Dash(ドアダッシュ)が日本進出!特徴は?Uber Eats(ウーバーイーツ)との違いについても